
Points clés à retenir
- Robots.txt est un fichier texte brut situé dans votre répertoire racine qui indique aux moteurs de recherche et aux robots d’exploration IA quelles pages de votre site explorer et lesquelles ignorer.
- En éloignant les robots du fouillis technique et des pages de faible valeur, vous vous assurez qu’ils consacrent leur temps au contenu important et de grande valeur qui génère des résultats.
- Les quatre robots d’exploration IA les plus intéressants à connaître (GPTBot, ClaudeBot, Google-Extended et CCBot) respectent les directives robots.txt et peuvent être bloqués individuellement avec leurs chaînes d’agent utilisateur.
- Les erreurs courantes du fichier robots.txt incluent l’utilisation interdire : / sur un site en ligne, bloquant les fichiers CSS ou JavaScript (ce qui nuit au rendu) et déroutant refuser avec sans index, puisqu’une page non autorisée peut toujours être indexée si elle est liée en externe.
Considérez votre fichier robots.txt comme le GPS de votre site.
Il indique aux robots d’exploration Web des moteurs de recherche comme Google ou Bing (et maintenant l’IA) où chercher et quoi indexer. C’est important dans le monde de la recherche d’aujourd’hui. Pourtant, c’est souvent une partie négligée de .
Beaucoup traitent le fichier robots.txt avec une mentalité de configuration et d’oubli, sans se rendre compte des conséquences que cela peut avoir sur la visibilité des recherches.
Alors que l’IA revendique désormais les premières positions sur les pages de résultats des moteurs de recherche (SERP), la bonne configuration robots.txt est plus importante que jamais.
Pour vous aider à garder une longueur d’avance, j’ai élaboré ce rappel sur la façon de créer un fichier robots.txt qui favorise une visibilité moderne et fournit de vrais résultats commerciaux.
Qu’est-ce qu’un fichier Robots.txt ?
Le fichier robots.txt, également connu sous le nom de protocole ou standard d’exclusion de robots, est un fichier texte qui indique aux robots Web (souvent les robots d’exploration des moteurs de recherche et les grattoirs d’IA) les pages de votre site à explorer.
Il indique également aux robots Web quelles pages pas explorer.
Supposons qu’un moteur de recherche soit sur le point de visiter un site. Avant de visiter la page cible, il vérifiera le fichier robots.txt pour obtenir des instructions.
Il existe différents types de fichiers robots.txt, examinons donc quelques exemples différents de leur apparence.
Disons que le moteur de recherche trouve :

Il s’agit du squelette de base d’un fichier robots.txt.
L’astérisque après « user-agent » indique que le fichier robots.txt s’applique à tous les robots Web visitant le site.
La barre oblique après « Interdire » indique au robot de ne visiter aucune page du site. Cependant, il est important de noter que le fait de refuser une page n’empêchera pas son indexation si des liens externes pointent vers cette page.
Pourquoi Robots.txt est important pour le référencement
Vous vous demandez peut-être pourquoi quelqu’un voudrait empêcher les robots Web de visiter son site.
Après tout, l’un des principaux objectifs des pratiques traditionnelles et consiste à permettre aux moteurs de recherche ou aux robots IA d’explorer facilement votre site, augmentant ainsi votre visibilité.
C’est là qu’intervient le secret de ce hack SEO.
Vous avez probablement beaucoup de pages sur votre site, n’est-ce pas ? Même si vous ne pensez pas le faire, vérifiez. Vous pourriez être surpris.
Si un moteur de recherche explore votre site, il explorera chaque page.
Et si vous avez beaucoup de pages, le robot du moteur de recherche mettra un certain temps à les explorer. Cela peut affecter négativement votre classement.
En effet, Googlebot (le robot du moteur de recherche de Google) dispose d’un « budget d’exploration ». Celui-ci se décompose en deux parties.
Le premier est la limite de capacité d’exploration, qui correspond au nombre maximum de connexions que Google peut utiliser pour explorer un site à un moment donné. ici:
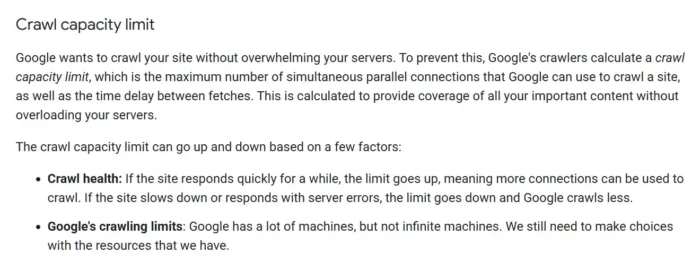
La deuxième partie est la demande d’exploration, qui correspond essentiellement à l’appétit de Google pour votre contenu. Cela dépend de la popularité de vos pages et de la fréquence à laquelle vous les mettez à jour. Voici un :

Fondamentalement, le budget d’exploration correspond à « le nombre d’URL que Googlebot peut et souhaite explorer ».
Vous souhaitez aider Googlebot à dépenser son budget d’exploration pour votre site aussi efficacement que possible. Cela signifie que vous souhaitez qu’il explore vos pages les plus précieuses.
Pour vous assurer que vous dirigez les robots vers les bons endroits, Google vous conseille de minimiser ces fuites courantes sur vos ressources d’exploration :
- Navigation à facettes : Les paramètres d’URL pour le tri et le filtrage peuvent créer un « espace infini » qui piège les robots dans un labyrinthe de pages redondantes.
- Contenu en double : Lorsque les mêmes informations existent sur plusieurs URL, consolidez-les pour que les robots d’exploration puissent se concentrer sur votre contenu unique.
- Obstacles et impasses : Les erreurs 404 logicielles et les longues chaînes de redirection gaspillent la demande d’exploration, obligeant les robots à travailler plus dur sans récompense.
- Performances du serveur : Si votre site répond lentement, Google risque de ne pas être en mesure de lire autant de contenu de votre site.
OK, revenons au fichier robots.txt.
Une page robots.txt bien structurée indique aux robots des moteurs de recherche (et en particulier à Googlebot) d’éviter certaines pages.
Pensez aux implications. En organisant votre fichier robots.txt, vous mettez en valeur votre meilleur travail. Vous éloignez efficacement les robots du désordre technique et les dirigez vers votre contenu le plus précieux.
En d’autres termes, votre robots.txt permet de garantir que chaque seconde qu’un robot passe sur votre domaine en vaut la peine. C’est la différence entre un robot qui se promène sans but dans votre stockage numérique et un autre qui se dirige directement vers les pages qui génèrent des résultats.
Intrigué par la puissance du fichier robots.txt ? Parlons de comment créer un fichier robots.txt et l’utiliser correctement.
Comment créer un fichier Robots.txt
Pour utiliser efficacement le fichier robots.txt, il faut commencer par maîtriser les bases. Suivez ces étapes pour créer un fichier robots.txt qui permet à votre « GPS de site Web » de démarrer du bon pied.
Étape 1 : ouvrez un éditeur de texte brut
Vous pouvez créer un nouveau fichier robots.txt à l’aide d’un éditeur de texte brut, comme le Bloc-notes sur PC et TextEdit sur Mac. Quoi que vous utilisiez, assurez-vous qu’il s’agit d’un éditeur de texte brut.
Si vous disposez déjà d’un fichier robots.txt, assurez-vous de supprimer le texte (mais pas le fichier) pour vous donner un nouveau départ.
Étape 2 : Localisez et formatez correctement votre fichier
Pour commencer, vous doit nommez votre fichier « robots.txt ». Cela peut sembler évident, mais c’est si important que cela mérite d’être souligné. Si vous vous trompez de nom, rien d’autre de ce que vous ferez n’aura d’importance.
Notez également que chaque site ne peut avoir qu’un seul fichier robots.txt. Ce fichier doit également être placé sur le domaine racine du site auquel il s’applique.
Google ici (nous résumons également les principaux points à retenir ci-dessous) :

Considérez-le comme les petits caractères techniques. Voici les trois éléments principaux à garder à l’esprit dans les conseils de Google :
- L’emplacement est primordial : Votre fichier doit résider à la racine de votre hébergeur (par exemple, votresite.com/robots.txt). Si vous le rangez dans un sous-dossier, les robots d’exploration ne le rechercheront tout simplement pas.
- Restez dans votre voie : Un fichier robots.txt n’a autorité que sur son protocole spécifique (HTTP ou HTTPS), son sous-domaine et son port. Si vous disposez d’un site mobile (m.votresite.com), il a besoin de son propre fichier dédié.
- Tenez-vous en à UTF-8 : Le fichier doit être un fichier texte brut avec un encodage UTF-8. Si vous utilisez des caractères non standard, Google pourrait trouver vos règles invalides et les ignorer complètement.
Étape 3 : Écrivez vos règles Robots.txt
Je vais vous montrer comment configurer un simple fichier robot.txt, en mettant en pratique les règles mentionnées ci-dessus.
Chaque fichier robots.txt commence par la directive user-agent. Cela définit quel crawlbot est soumis à la règle. Cet exemple tiré de la documentation robots.txt de Google définit Googlebot comme utilisateur.
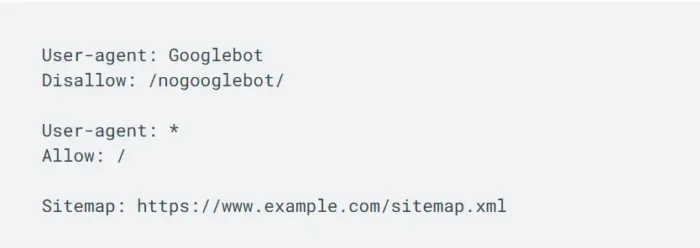
L’exemple définit également deux règles : autoriser et interdire. Ils permettent au fichier robots.txt de guider Googlebot vers n’importe quelle page du domaine racine www.example.com, à l’exception de celles dont le chemin d’URL est /nogooglebot/. Tous les autres robots d’exploration sont libres d’explorer n’importe quelle page du site.
Je sais que cela semble super simple, mais ces deux lignes font déjà beaucoup.
Cette règle est également liée à un , mais ce n’est pas strictement nécessaire. Il sert de carte universelle pour tous les robots d’exploration, y compris l’IA. C’est particulièrement important pour les sites de grande taille, car cela donne aux robots un chemin direct vers vos pages les plus précieuses sans qu’ils aient à rechercher des liens.
Voilà, vous disposez désormais d’un fichier robots.txt de base avec des règles simples (mais efficaces).
Au fur et à mesure que vous vous familiariserez avec l’utilisation de robots.txt, vous pourrez utiliser davantage de règles à votre avantage. Google les répertorie tous, ainsi que ce qu’ils font, .
Étape 4 : Enregistrez et téléchargez dans votre répertoire racine
Pour faire son travail, votre fichier robots.txt doit être téléchargé dans le répertoire racine de votre site. La manière de procéder dépend de votre plate-forme d’hébergement et de l’architecture de votre site.
Une exception courante à cette règle est WordPress, qui peut générer son propre fichier robots.txt virtuel lorsque vous lancez un site. Pour le modifier, vous aurez peut-être besoin d’un plug-in ou d’une importation manuelle pour le remplacer.
En cas de doute, contactez votre plate-forme d’hébergement ou recherchez dans sa documentation d’assistance les méthodes de téléchargement. Vous pouvez généralement le faire en accédant à leurs articles d’aide ou à leur base de connaissances et en recherchant “télécharger des fichiers [nom de la société d’hébergement]”.
Comment bloquer les robots d’exploration IA avec Robots.txt
Le blocage des robots d’exploration IA vous donne plus de contrôle sur la façon dont votre contenu est utilisé.
Certains propriétaires de sites le font pour limiter l’utilisation de la formation à l’IA. D’autres le font pour réduire la charge du robot d’exploration, protéger le contenu de type fermé devenu public accidentellement ou empêcher les concurrents de reconditionner leur travail via des outils d’IA.
Le compromis est la visibilité. Si vous bloquez tout, vous pouvez protéger une plus grande partie de votre contenu, mais vous pouvez également réduire vos chances d’apparaître dans les résultats générés par l’IA.
Les principaux robots d’exploration d’IA à connaître sont GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google) et CCBot (Common Crawl). Les quatre prennent en charge les contrôles robots.txt et chacun publie une chaîne d’agent utilisateur spécifique que vous pouvez cibler.
CCBot est une solution que beaucoup de gens négligent, même si son ensemble de données publiques alimente des dizaines de modèles open source, ce qui la rend trop percutante pour être laissée de côté.
Pour bloquer chaque robot d’exploration individuellement, répertoriez chaque agent utilisateur avec sa propre règle d’interdiction :
Agent utilisateur : GPTBot
Interdire : /
Agent utilisateur : ClaudeBot
Interdire : /
Agent utilisateur : Google Extended
Interdire : /
Agent utilisateur : CCBot
Interdire : /
Les principaux robots d’exploration d’IA qu’il vaut la peine de connaître couvrent à la fois les fonctions de formation et de recherche. OpenAI exécute GPTBot pour la formation et OAI-SearchBot pour la recherche. Anthropic exécute ClaudeBot pour la formation et Claude-SearchBot pour la recherche. Google utilise Google-Extended pour la formation. CCBot, géré par Common Crawl, alimente des dizaines de modèles open source, cela vaut donc la peine de l’inclure même si de nombreuses personnes l’ignorent.
Cette distinction est importante dans la pratique. Le blocage de GPTBot ne bloque pas OAI-SearchBot, et le blocage de ClaudeBot ne bloque pas Claude-SearchBot. Si vous souhaitez arrêter à la fois l’entraînement et l’exploration de recherche, vous avez besoin de règles distinctes pour chaque bot.
Tous ces robots d’exploration prennent en charge les contrôles robots.txt et chacun publie une chaîne d’agent utilisateur spécifique que vous pouvez cibler. Pour les bloquer individuellement, répertoriez chaque agent utilisateur avec sa propre règle d’interdiction :
Agent utilisateur : GPTBot
Interdire : /
Agent utilisateur : OAI-SearchBot
Interdire : /
Agent utilisateur : ClaudeBot
Interdire : /
Agent utilisateur : Claude-SearchBot
Interdire : /
Agent utilisateur : interdiction étendue de Google :
Agent utilisateur : CCBot Interdire : /
Si vous préférez bloquer tous les robots autres que les recherches en même temps, inversez la logique. Interdisez tout par défaut, puis autorisez explicitement les moteurs de recherche que vous souhaitez conserver.
Agent utilisateur : *
Interdire : /
Agent utilisateur : Googlebot
|Autoriser : /
Agent utilisateur : Bingbot
Permettre: /
Notez que Google-Extended est un jeton distinct de Googlebot. Le bloquer vous exclut des données de formation sur l’IA de Google et n’a aucun effet sur votre classement dans la recherche Google standard.
Gardez à l’esprit que si le blocage des robots d’exploration de l’IA empêche votre contenu d’alimenter la formation des modèles, cela réduit également vos chances d’être cité dans les réponses de l’IA. Il est important de procéder avec prudence si vous souhaitez mettre en œuvre ces règles.
Si la visibilité de l’IA fait partie de votre stratégie, utilisez un pour guider les systèmes d’IA vers votre meilleur contenu plutôt que de les verrouiller complètement, comme vous le feriez avec votre fichier robots.txt.
Comment tester votre fichier Robots.txt
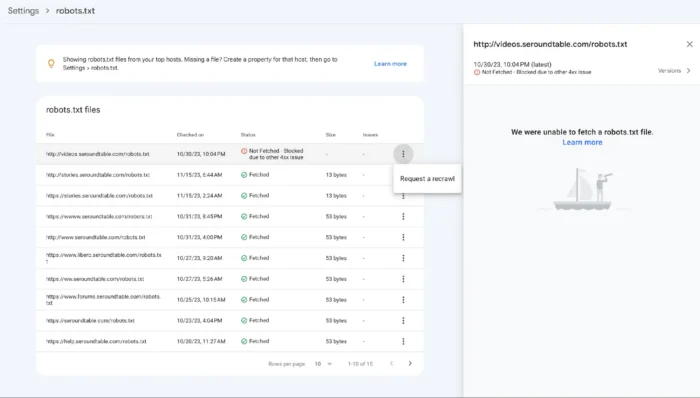
Une fois votre fichier robots.txt mis en ligne, confirmez que Google peut le lire correctement. Google a retiré l’ancien testeur robots.txt autonome fin 2023 et l’a remplacé par le dans Google Search Console.
Pour le trouver, ouvrez la Search Console, sélectionnez votre propriété, puis cliquez sur Paramètres dans la barre latérale gauche. Le rapport indique quels fichiers robots.txt Google a récupérés pour votre site, quand chacun a été exploré pour la dernière fois, ainsi que les erreurs de syntaxe ou les avertissements rencontrés lors de l’analyse. Si vous venez de publier une mise à jour, vous pouvez demander une nouvelle analyse directement depuis cet écran.
Pour tester le comportement d’une URL spécifique selon vos règles actuelles, passez à . Il vous indique si Googlebot peut accéder à la page ou si une directive la bloque.
Cette décision est utile pour détecter une règle d’interdiction égarée avant qu’elle ne génère une page importante. Intégrez cela à votre routine .

Autre conseil de pro : Saisissez le domaine racine suivi de /robots.txt dans votre navigateur pour afficher le fichier robots.txt de ce site. C’est un moyen rapide de voir comment les concurrents structurent leurs règles, quels répertoires ils protègent et quels robots d’exploration IA ils bloquent.
Associez-le à un plein pour une image complète des domaines dans lesquels vous pouvez améliorer et dépasser vos concurrents.
Erreurs Robots.txt courantes à éviter
Les erreurs Robots.txt sont faciles à commettre et difficiles à repérer jusqu’à ce que le trafic diminue. Même de petites erreurs peuvent avoir des conséquences sur l’ensemble du site.
Voici les faux pas les plus courants à surveiller :
- Utilisation de disallow : / sur un site en direct. Cette seule ligne bloque chaque URL de votre site à partir de chaque robot d’exploration, y compris votre page d’accueil. Il passe généralement en production lorsqu’un fichier intermédiaire est mis en ligne sans être mis à jour. Assurez-vous donc de revoir votre fichier robots.txt après chaque migration.
- Blocage CSS et JavaScript. Googlebot affiche vos pages de la même manière qu’un navigateur. Il a donc besoin d’accéder à vos fichiers CSS, JavaScript et image pour les évaluer correctement. Le blocage de ces ressources peut forcer Google à explorer votre site “à l’aveugle”, ce qui entraînerait une rétrogradation dans le classement.
- Confondre disallow avec noindex. Une règle d’interdiction arrête l’exploration mais n’empêche pas l’indexation. Une URL bloquée peut toujours apparaître dans la recherche Google si elle est liée à partir d’un autre site. Pour qu’une page ne figure pas dans les résultats de recherche, utilisez plutôt une balise Meta noindex ou protégez la page par mot de passe.
- Laisser le fichier vide ou manquant. Un robots.txt manquant ne détruira pas votre site. Google supposera que tout peut être exploré, mais vous perdez la possibilité de diriger les robots d’exploration vers votre plan de site, de gérer le budget d’exploration ou de désactiver les robots d’exploration IA. Intégrez-le à votre statut donc ce n’est pas une réflexion après coup.
FAQ
Comment fonctionne le fichier robots.txt ?
Les robots d’exploration vérifient yoursite.com/robots.txt avant d’explorer vos pages. Le fichier utilise des directives d’agent utilisateur et d’interdiction pour leur indiquer les chemins à ignorer. La conformité est volontaire, mais les principaux robots d’exploration la respectent.
Ai-je besoin d’un fichier robots.txt ?
Pas nécessairement. Google peut explorer votre site sans en avoir un, mais le fichier vous permet de contrôler le budget d’exploration et de bloquer les robots d’exploration de l’IA, ce qui vaut la peine, même pour les petits sites.
À quoi doit ressembler un fichier robots.txt ?
Un fichier minimal qui autorise tous les robots et pointe vers votre plan de site ressemble à ceci :
Agent utilisateur : *
Refuser:
Plan du site : https://votresite.com/sitemap.xml
Ajoutez des règles d’interdiction pour tous les répertoires que vous ne souhaitez pas explorer, comme /wp-admin/ ou /checkout/. Utilisez un bloc user-agent distinct par robot d’exploration auquel vous souhaitez attribuer des règles différentes.
Comment modifier le fichier robots.txt dans WordPress ?
Le chemin le plus simple est un plugin SEO comme Yoast, qui inclut un éditeur robots.txt dans ses paramètres. Sinon, modifiez le fichier via FTP ou votre gestionnaire de fichiers d’hébergement et téléchargez-le dans le répertoire racine de votre site.
Comment puis-je corriger « Indexé, bien que bloqué par robots.txt ? »
Cet avertissement signifie que Google a indexé une URL qu’il n’a pas pu explorer. Supprimez la règle d’interdiction afin que Google puisse lire la balise noindex de votre page, ou protégez (ou supprimez) entièrement la page par mot de passe.
Conclusion
Robots.txt est un petit fichier qui a un impact important sur la façon dont votre site s’affiche sur le Web. Quelques directives bien placées peuvent exclure les pages de faible valeur des résultats de recherche et décider si les systèmes d’IA doivent s’entraîner sur votre contenu.
Vous disposez déjà d’un fichier robots.txt ? Vérifiez-le par rapport aux erreurs décrites ci-dessus.
Repartir de zéro ? Créez-le en suivant les étapes de ce guide et testez-le dans la Search Console avant de le terminer.
La conversation autour du fichier robots.txt a changé. Ce qui a commencé comme un outil de gestion de Googlebot et des SERP s’étend désormais à la gestion de l’essor de l’IA dans la recherche et des normes émergentes comme llms.txt.
Quoi qu’il en soit, le fichier robots.txt reste un élément fondamental pour garder le contrôle de votre contenu.